
Yes, you heard that right! JSON, the ubiquitous format for data interchange in web development, might be slowing down your applications. In a world where speed and responsiveness are paramount, it’s crucial to examine the performance implications of JSON, a technology we often take for granted. In this blog, we’ll dive deep into the reasons why JSON can be a bottleneck in your applications and explore faster alternatives and optimization techniques to keep your apps running at their best.
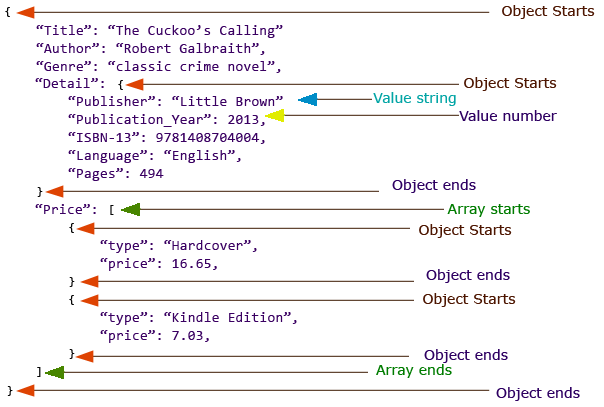
JSON, short for JavaScript Object Notation, is a lightweight data interchange format that has become the go-to choice for transmitting and storing data in web applications. Its simplicity and human-readable format make it easy for both humans and machines to work with. But why should you care about JSON in the context of your web development projects?
JSON is the glue that holds together the data in your applications. It’s the language in which data is communicated between servers and clients, and it’s the format in which data is stored in databases and configuration files. In essence, JSON plays a pivotal role in modern web development.
Understanding JSON and its nuances is not only a fundamental skill for any web developer but also crucial for optimizing your applications. As we delve deeper into this blog, you’ll discover why JSON can be a double-edged sword when it comes to performance and how this knowledge can make a significant difference in your development journey.
JSON’s popularity in the world of web development can’t be overstated. It has emerged as the de facto standard for data interchange for several compelling reasons:https://cdn.embedly.com/widgets/media.html?src=https%3A%2F%2Ftenor.com%2Fembed%2F12757531483676458464&display_name=Tenor&url=https%3A%2F%2Ftenor.com%2Fview%2Fit%27s-easy-to-use-ignace-aleya-user-friendly-easy-not-that-hard-gif-12757531483676458464&image=https%3A%2F%2Fmedia.tenor.com%2FsQvbSsdlveAAAAAC%2Fit%2527s-easy-to-use-ignace-aleya.gif&key=a19fcc184b9711e1b4764040d3dc5c07&type=text%2Fhtml&schema=tenorIt’s just easy to use!
Given these advantages, it’s no wonder that developers across the globe rely on JSON for their data interchange needs. However, as we explore deeper into the blog, we’ll uncover the potential performance challenges associated with JSON and how to address them effectively.
In today’s fast-paced digital landscape, application speed and responsiveness are non-negotiable. Users expect instant access to information, swift interactions, and seamless experiences across web and mobile applications. This demand for speed is driven by several factors:
Now, let’s address the central question: Is JSON slowing down our applications?
JSON, as mentioned earlier, is an immensely popular data interchange format. It’s flexible, easy to use, and widely supported. However, this widespread adoption doesn’t make it immune to performance challenges.
JSON, in certain scenarios, can be a culprit when it comes to slowing down applications. The process of parsing JSON data, especially when dealing with large or complex structures, can consume valuable milliseconds. Additionally, inefficient serialization and deserialization can impact an application’s overall performance.
In the sections that follow, we’ll explore the specific reasons why JSON can be a bottleneck in your applications and, more importantly, how to mitigate these issues. As we go farther ahead, keep in mind that our goal is not to discredit JSON but to understand its limitations and discover strategies for optimizing its performance in the pursuit of faster, more responsive applications.
JSON, despite its widespread use, isn’t immune to performance challenges. Let’s explore the reasons behind JSON’s potential slowness and understand why it might not always be the speediest choice for data interchange.
When JSON data arrives at your application, it must undergo a parsing process to transform it into a usable data structure. Parsing can be relatively slow, especially when dealing with extensive or deeply nested JSON data.
JSON requires data to be serialized (encoding objects into a string) when sent from a client to a server and deserialized (converted the string back into usable objects) upon reception. These steps can introduce overhead and affect your application’s overall speed.
In the world of microservices architecture, JSON is often used for passing messages between services. However, it’s crucial to recognize that JSON messages require serialization and deserialization, processes that can introduce significant overhead.
In scenarios with numerous microservices communicating constantly, this overhead can add up and potentially slow down your applications to an extent that affects user experience.
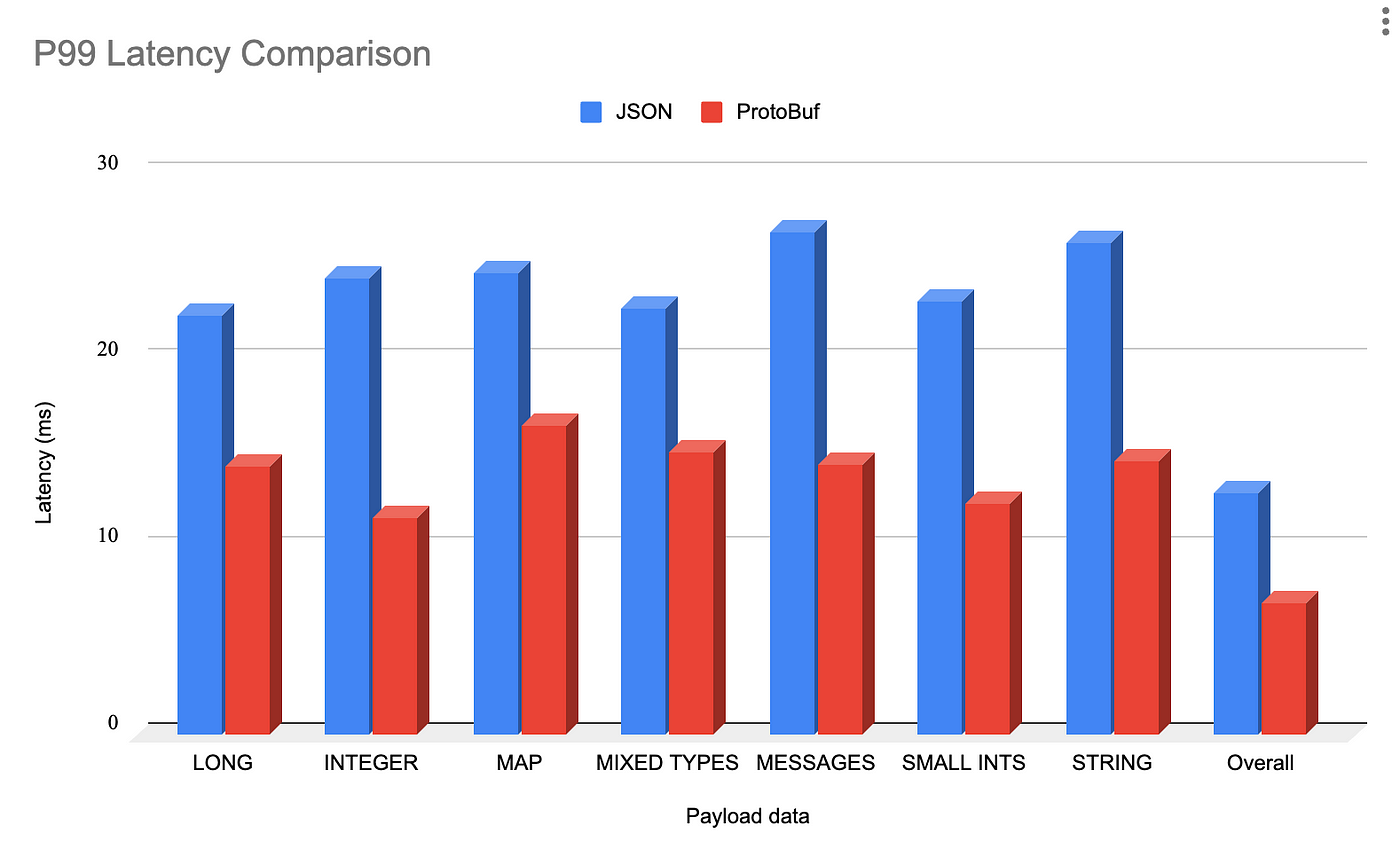
The second challenge we faced was that due to the textual nature of JSON, serialization and deserialization latency and throughput were suboptimal.
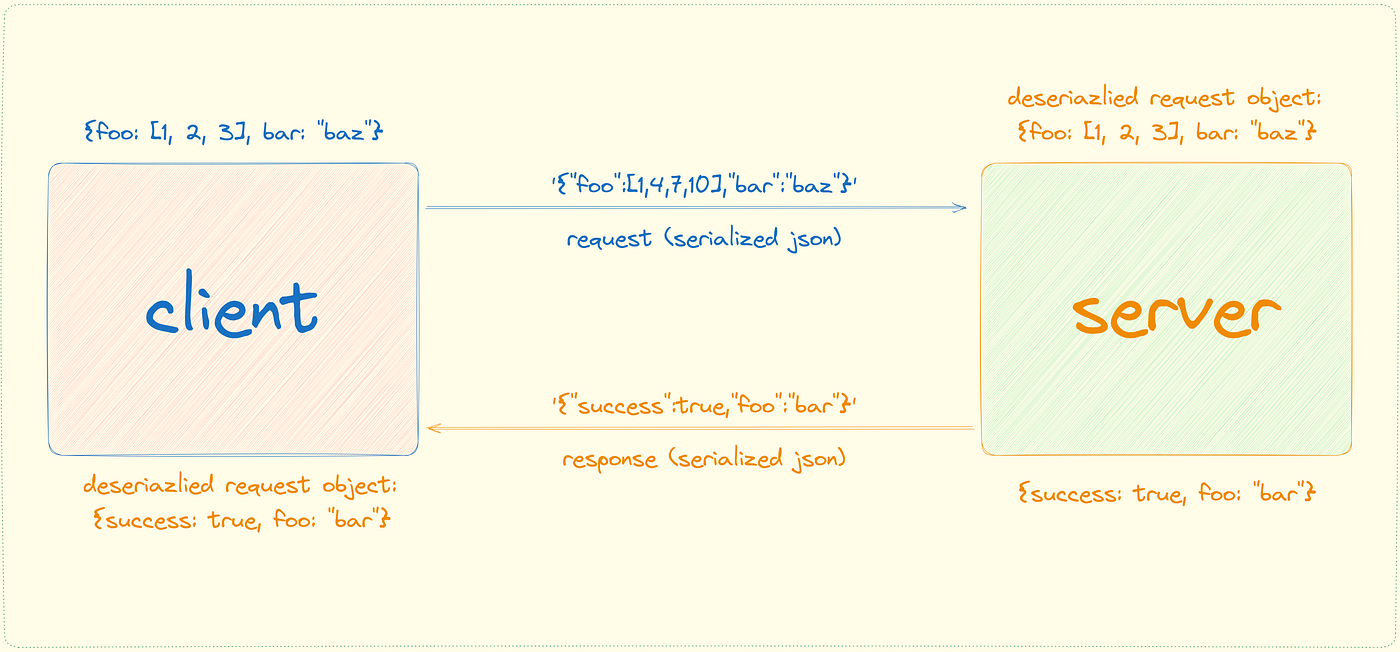
JSON is text-based, relying heavily on string manipulation for operations like concatenation and parsing. String handling can be slower compared to working with binary data.
JSON has a limited set of data types (e.g., strings, numbers, booleans). Complex data structures might need less efficient representations, leading to increased memory usage and slower processing.
JSON’s human-readable design can result in verbosity. Redundant keys and repetitive structures increase payload size, causing longer data transfer times.
The first challenge is that JSON is a textual format, which tends to be verbose. This results in increased network bandwidth usage and higher latencies, which is less than ideal.
JSON lacks native support for binary data. When dealing with binary data, developers often need to encode and decode it into text, which can be less efficient.
In some scenarios, JSON data can be deeply nested, requiring recursive parsing and traversal. This computational complexity can slow down your application, especially without optimization.
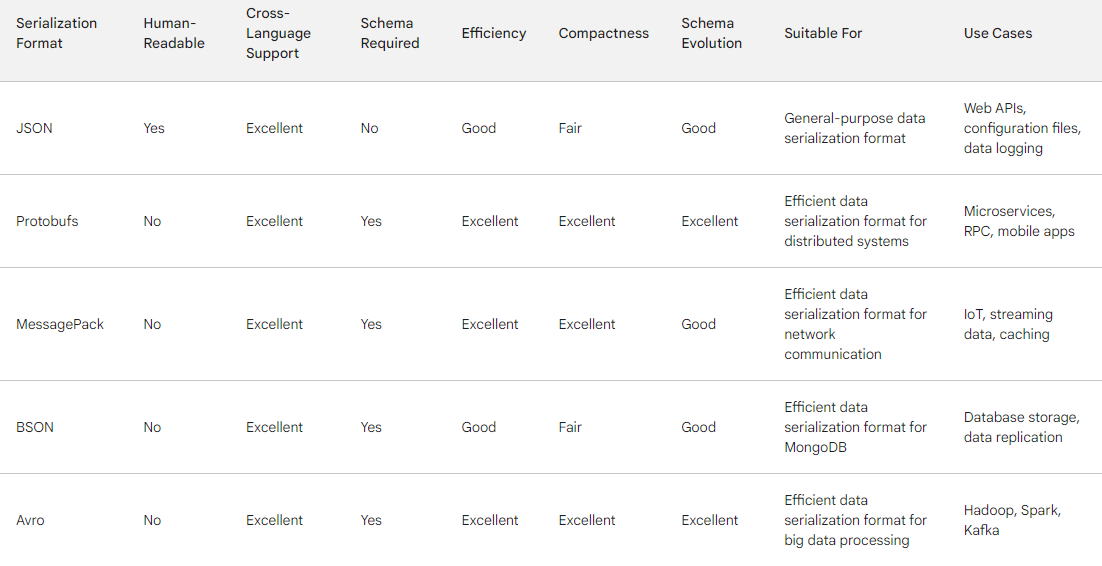
While JSON is a versatile data interchange format, its performance limitations in certain scenarios have led to the exploration of faster alternatives. Let’s delve into some of these alternatives and understand when and why you might choose them:
Protocol Buffers, often referred to as protobuf, are a binary serialization format developed by Google. They are designed for efficiency, compactness, and speed. Protobuf’s binary nature makes it significantly faster than JSON for serialization and deserialization.
MessagePack is another binary serialization format known for its speed and compactness. It’s designed to be more efficient than JSON while maintaining compatibility with various programming languages.
BSON, or Binary JSON, is a binary-encoded format derived from JSON. It retains JSON’s flexibility while improving performance through binary encoding. BSON is commonly used in databases like MongoDB.
Apache Avro is a data serialization framework that focuses on providing a compact binary format. It’s schema-based, allowing for efficient data encoding and decoding.
These alternatives offer varying degrees of performance improvements over JSON, and the choice depends on your specific use case. By considering these alternatives, you can optimize your application’s data interchange processes, ensuring that speed and efficiency are at the forefront of your development efforts.
In the world of data interchange, where efficiency and speed are paramount, the choice of data format can make a world of difference. This section explores the journey from a simple JSON data representation to more efficient binary formats like Protocol Buffers, MessagePack, BSON, and Avro. We’ll delve into the nuances of each format and demonstrate why every byte matters.
We start our journey with a straightforward JSON data structure. Here’s a snippet of our sample JSON data:
{
"id": 1, // 14 bytes
"name": "John Doe", // 20 bytes
"email": "[email protected]", // 31 bytes
"age": 30, // 9 bytes
"isSubscribed": true, // 13 bytes
"orders": [ // 11 bytes
{ // 2 bytes
"orderId": "A123", // 18 bytes
"totalAmount": 100.50 // 20 bytes
}, // 1 byte
{ // 2 bytes
"orderId": "B456", // 18 bytes
"totalAmount": 75.25 // 19 bytes
} // 1 byte
] // 1 byte
} // 1 byte
Total JSON Size: ~139 bytes
While JSON is versatile and easy to work with, it has a drawback — its textual nature. Each character, each whitespace, and every quotation mark matters. In scenarios where data size and transmission speed are critical, these seemingly trivial characters can have a significant impact.

Now, let’s provide data representations for other formats and compare their sizes:
syntax = "proto3";
message User {
int32 id = 1;
string name = 2;
string email = 3;
int32 age = 4;
bool is_subscribed = 5;
repeated Order orders = 6;
message Order {
string order_id = 1;
float total_amount = 2;
}
}
0A 0E 4A 6F 68 6E 20 44 6F 65 0C 4A 6F 68 6E 20 44 6F 65 65 78 61 6D 70 6C 65 2E 63 6F 6D 04 21 00 00 00 05 01 12 41 31 32 33 03 42 DC CC CC 3F 05 30 31 31 32 34 34 35 36 25 02 9A 99 99 3F 0D 31 02 42 34 35 36 25 02 9A 99 99 3F
Total Protocol Buffers Size: ~38 bytes
(Note: MessagePack is a binary format, and the representation here is not human-readable.)
Binary Representation (Hexadecimal):
a36a6964000000000a4a6f686e20446f650c6a6f686e646f65406578616d706c652e636f6d042100000005011241313302bdcccc3f0530112434353625029a99993f
Total MessagePack Size: ~34 bytes
(Note: BSON is a binary format, and the representation here is not human-readable.)
Binary Representation (Hexadecimal):
3e0000001069640031000a4a6f686e20446f6502656d61696c006a6f686e646f65406578616d706c652e636f6d1000000022616765001f04370e4940
Total BSON Size: ~43 bytes
(Note: Avro uses a schema, so the data is encoded along with schema information.)
Binary Representation (Hexadecimal):
0e120a4a6f686e20446f650c6a6f686e646f65406578616d706c652e636f6d049a999940040a020b4108312e3525312e323538323539
Total Avro Size: ~32 bytes

Now you might be wondering why even though some of these formats output binary, they have varied sizes. Binary formats like Avro, MessagePack, and BSON have different internal structures and encoding mechanisms, which can result in variations in the binary representations even though they ultimately represent the same data. Here’s a brief overview of how these differences arise:
These differences in design and encoding result in variations in the binary representations:
In summary, these differences arise from the design goals and features of each format. Avro prioritizes schema compatibility, MessagePack focuses on compactness, and BSON maintains JSON-like structures with added binary types. The choice of format depends on your specific use case and requirements, such as schema compatibility, data size, and ease of use.
JSON, while incredibly versatile and widely adopted in web development, is not without its speed challenges. The format’s human-readable nature can result in larger data payloads and slower processing times. So, the question arises: How can we optimize JSON to make it faster and more efficient? In this guide, we’ll explore practical strategies and optimizations that can be implemented to enhance JSON’s performance, ensuring that it remains a valuable tool in modern web development while delivering the speed and efficiency your applications demand.
Here are some practical tips for optimizing JSON performance, along with code examples and best practices:
// Inefficient
{
"customer_name_with_spaces": "John Doe"
}
// Efficient
{
"customerName": "John Doe"
}
// Inefficient
{
"transaction_type": "purchase"
}
// Efficient
{
"txnType": "purchase"
}
// Inefficient
{
"order": {
"items": {
"item1": "Product A",
"item2": "Product B"
}
}
}
// Efficient
{
"orderItems": ["Product A", "Product B"]
}
// Inefficient
{
"quantity": 1.0
}
// Efficient
{
"quantity": 1
}
// Inefficient
{
"product1": {
"name": "Product A",
"price": 10
},
"product2": {
"name": "Product A",
"price": 10
}
}
// Efficient
{
"products": [
{
"name": "Product A",
"price": 10
},
{
"name": "Product B",
"price": 15
}
]
}
// Node.js example using zlib for Gzip compression
const zlib = require('zlib');
const jsonData = {
// Your JSON data here
};
zlib.gzip(JSON.stringify(jsonData), (err, compressedData) => {
if (!err) {
// Send compressedData over the network
}
});
Remember that the specific optimizations you implement should align with your application’s requirements and constraints.
In this section, we dive into real-world applications and projects that encountered performance bottlenecks with JSON and successfully addressed them. We’ll explore how organizations tackled JSON’s limitations and the tangible benefits these optimizations brought to their applications. From renowned platforms like LinkedIn and Auth0 to disruptive tech giants like Uber, these examples offer valuable insights into the strategies employed to boost speed and responsiveness while still leveraging the versatility of JSON, if possible.
These real-world examples demonstrate how addressing JSON’s performance challenges with optimization strategies can have a substantial positive impact on application speed, responsiveness, and user experience. They highlight the importance of considering alternative data formats and efficient data structures to overcome JSON-related slowdowns in various scenarios.
In the world of development, JSON stands as a versatile and indispensable tool for data interchange. Its human-readable format and cross-language compatibility have made it a cornerstone of modern applications. However, as we’ve explored in this guide, JSON’s widespread adoption doesn’t exempt it from performance challenges.
The key takeaways from our journey into optimizing JSON performance are clear:
As you continue to build and enhance your web applications, remember to consider the performance implications of JSON. Carefully design your data structures, choose meaningful key names, and explore alternative serialization formats when necessary. By doing so, you can ensure that your applications not only meet but exceed user expectations in terms of speed and efficiency.
In the ever-evolving landscape of web development, optimizing JSON performance is a valuable skill that can set your projects apart and ensure that your applications thrive in the era of instant digital experiences.
Source: Medium
 Blogs
Blogs
